| A. Equal bang for the buck | B. Cost of sharing resources | C. Diminishing returns from contention | D. Negative returns from incoherency |
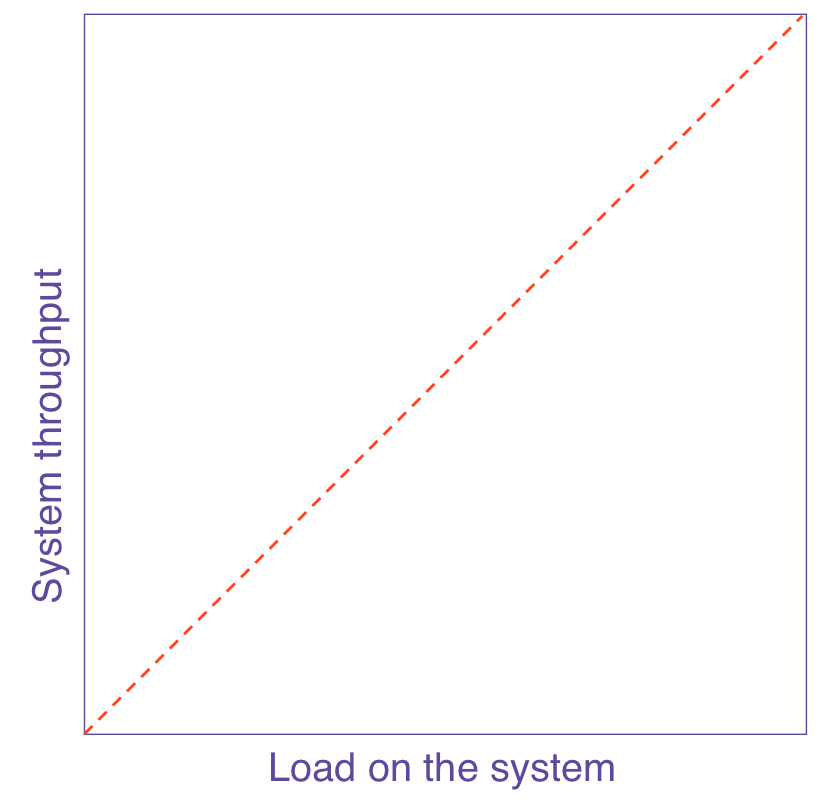 |  |  |  |
| α = 0, β = 0 | α > 0, β = 0 | α >> 0, β = 0 | α >> 0, β > 0 |
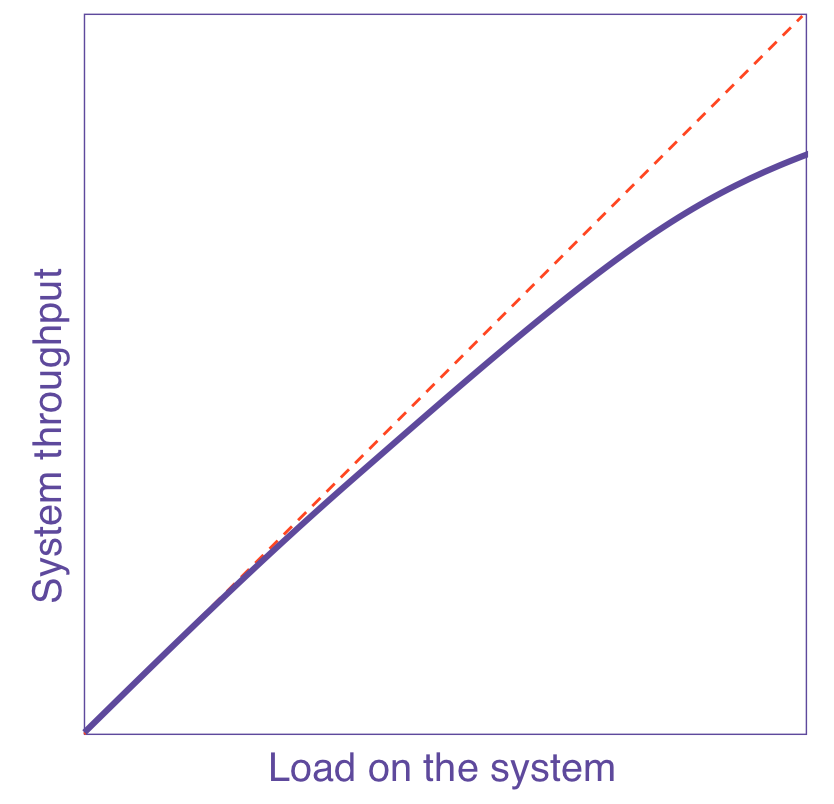
| A. Equal bang for the buck | B. Cost of sharing resources | C. Diminishing returns from contention | D. Negative returns from incoherency |
| | | | |
| α = 0, β = 0 | α > 0, β = 0 | α >> 0, β = 0 | α >> 0, β > 0 |
| (1) |
| (2) |
| (3) |
NOTE: The objective of using eqn.(3) is NOT to produce a curve that passes through every data point. That's called curve fitting and that's what graphics artists do with splines. As von Neumann said, "Give me 4 parameters and I'll fit an elephant. Give me 5 and I'll make its trunk wiggle!" (At least I only have 2)The fitted coefficients in eqn.(3) then provide an estimate of the user load at which the maximum scalability will occur in case D:
| (4) |
| (5) |
Amdahl's law for parallel speedup is equivalent to the synchronous queueing bound on throughput in the machine repairman model of a multiprocessor.
The USL is equivalent to the synchronous queueing bound on throughput for a linear load-dependent machine repairman model of a multiprocessor.The proof can be found in [Gunther 2008]. Amdahl's law is therefore subsumed by the USL because it corresponds to the case β = 0. Both Amdahl's law and the USL belong to a class of mathematical functions called Rational Functions. Moreover, these theorems have also been confirmed experimentally using event-driven simulations [HoltGun 2008]. In other words, the whole USL approach to quantifying scalability rests on a fundamentally sound physical footing.


Note that this Excel file contains the reorganized version of the USL equation as it appears in the Guerrilla Capacity Planning book:The difference in the USL versions (old and current) has to do with the way the coefficients are included in the USL equation and therefore how they are calculated from the fitting parameters a and b in Excel. This only applies to the Excel version of the USL, where an inversion transformation is necessary because Excel cannot fit a rational function by default. Tools like R and Mathematica do not have this limitation.
- Current hardware equation (5.1) which uses the coefficients labeled σ and κ.
- Current software equation (6.7) which uses the coefficients labeled α and β.
Applying The Universal Scalability Law to Distributed Systems When I originally developed the Universal Scalability Law (USL), it was in the context of tightly-coupled Unix multiprocessors [Gunther 1993], which led to an inherent dependency between the serial contention term and the data consistency term in the USL, i.e., no contention, no coherency penalty. A decade later, I realized that the USL would have broader applicability to distributed clusters if this dependency was removed [Gunther 2007]. In this talk I will show examples of how the most recent version of the USL, with three parameters α, β, γ, can be applied as a statistical regression model to a variety of large-scale distributed systems, such as Hadoop, Zookeeper, Sirius, AWS cloud, and Avalanche DLT, in order to quantify their scalability in terms of numerical concurrency, contention, and coherency values.Video
The Data Analytics of Application Scaling and Why There Are No Giants Like the 30 ft. giant in "Jack and the Beanstalk," myths and fallacies abound regarding application scaling. Many blog posts show some performance data as time-series charts, but otherwise only offer a qualitative analysis. This talk is intended to remedy that by showing you how to QUANTIFY scalability. Time series are not sufficient to assess cost-benefit of cloud services and other scalability trade-offs. After reviewing the nonlinear constraints on the scalability of giants, we apply similar nonlinear data-analytics techniques to determine the universal scalability constraints on such well-known applications as: MySQL, Memcache, NGINX, Zookeeper, and Amazon AWS.Video
Hadoop Superlinear Scalability [Hadoop 2015] "We often see more than 100% speedup efficiency!" came the rejoinder to the innocent reminder that you cannot have more than 100% of anything. This was just the first volley from software engineers during a presentation on how to quantify computer-system scalability in terms of the speedup metric. In different venues, on subsequent occasions, that retort seemed to grow into a veritable chorus that not only was superlinear speedup commonly observed, but also the model used to quantify scalability for the past 20 years—Universal Scalability Law (USL)—failed when applied to superlinear speedup data. Indeed, superlinear speedup is a bona fide phenomenon that can be expected to appear more frequently in practice as new applications are deployed onto distributed architectures. As demonstrated here using Hadoop MapReduce, however, the USL is not only capable of accommodating superlinear speedup in a surprisingly simple way, it also reveals that superlinearity, although alluring, is as illusory as perpetual motion.ACM Queue Video at CACM
Super Sizing Your Servers and the Payback Trap As part of IT management, system administrators and ops managers need to size servers and clusters to meet application performance targets; whether it be for a private infrastructure or a public cloud. In this talk I will first establish an analytic framework that can quantify linear, sublinear and negative scalability. This framework can easily be incorporated into Google Docs or R. Several examples including PostgreSQL, Memcached, Varnish and Amazon EC2 scalability will then be presented in detail. The lesser known phenomenon of superlinearity will be examined using this same framework. Superlinear scaling means achieving more performance than the available capacity would be expected to support.Slides and video
Brooks, Cooks and Response Time Scalability Successful database scaling to meet service level objectives (SLO) requires converting standard Oracle performance data into a form suitable for cost-benefit comparison, otherwise you are likely to be groping in the dark or simply relying on someone else's scalability recipes. Creating convenient cost-benefit comparisons is the purpose of the Universal Scalability Law (USL), which I have previously presented using transaction throughput measurements as the appropriate performance metric. However, Oracle AWR and OWI data are largely based on response time metrics rather than throughput metrics. In this presentation, I will show you how the USL can be applied to response time data. A surprising result is that the USL contains Brooks' law, which is essentially a variant of the old too-many-cooks adage: hiring more cooks at the last minute to ensure the meal is prepared on time can cause the preparation to take longer. From the standpoint of the USL, this kind of delay inflation arises from two unique interactions in the kitchen: group conferences and tête-à-têtes between the experienced cooks and the rookie cooks. Replace cooks with Oracle average active sessions (AAS) and similar response-time inflation can impact your database SLOs. The USL reveals this effect in a numerical way for easier analysis. Examples of applying the USL to Oracle performance data will be used to examine Brooks' law and underlying concepts such as delay, wait, latency, averages and response time percentiles.Presentation slides (PDF)
Quantifying Scalability FTW You probably already collect performance data, but data ain't information. Successfull scalability requires transforming your data so that you can quantify the cost-benefit of any architectural decisions. In other words:Speaker listSo, measurement alone is only half the story; you need a method to transform your data. In this presentation I will show you a method that I have developed and applied successfully to large-scale web sites and stack applications to quantify the benefits of proposed scaling strategies. To the degree that you don't quantify your scalability, you run the risk of ending up with WTF rather than FTW.
measurement + models == information
Hidden Scalability Gotchas in Memcached and Friends* Neil Gunther (Performance Dynamics), Shanti Subramanyam (Oracle USA), Stefan Parvu (Oracle Finland) Most web deployments have standardized on horizontal scaleout in every tier: web, application, caching and database; using cheap, off-the-shelf, white boxes. In this approach, there are no real expectations for vertical scalability of server apps like memcached or the full LAMP stack. But with the potential for highly concurrent scalability offered by newer multicore processors, it is no longer cost-effective to ignore their underutilization due to poor, thread-level, scalability of the web stack. In this session we show you how to quantify scalability with the Universal Scalability Law (USL) by demonstrating its application to actual performance data collected from a memcached benchmark. As a side effect of our technique, you will see how the USL also identifies the most signficant performance tuning opportunities to improve web app scalability.* This work was performed while two of us (S.S. and S.P.) were employed by Sun Microsystems, prior to its acquisition by Oracle Corporation. Cite as:
N. J. Gunther, S. Subramanyam, and S. Parvu. "Hidden Scalability Gotchas in Memcached and Friends." In VELOCITY Web Performance and Operations Conference, Santa Clara, California, O'Reilly, June, 22-24 2010.Presentation slides (PDF) Blog post about being accepted for the Velocity 2010 conference Web Ops track. My review of the conference.
http://velocityconf.com/velocity2010/public/schedule/detail/13046
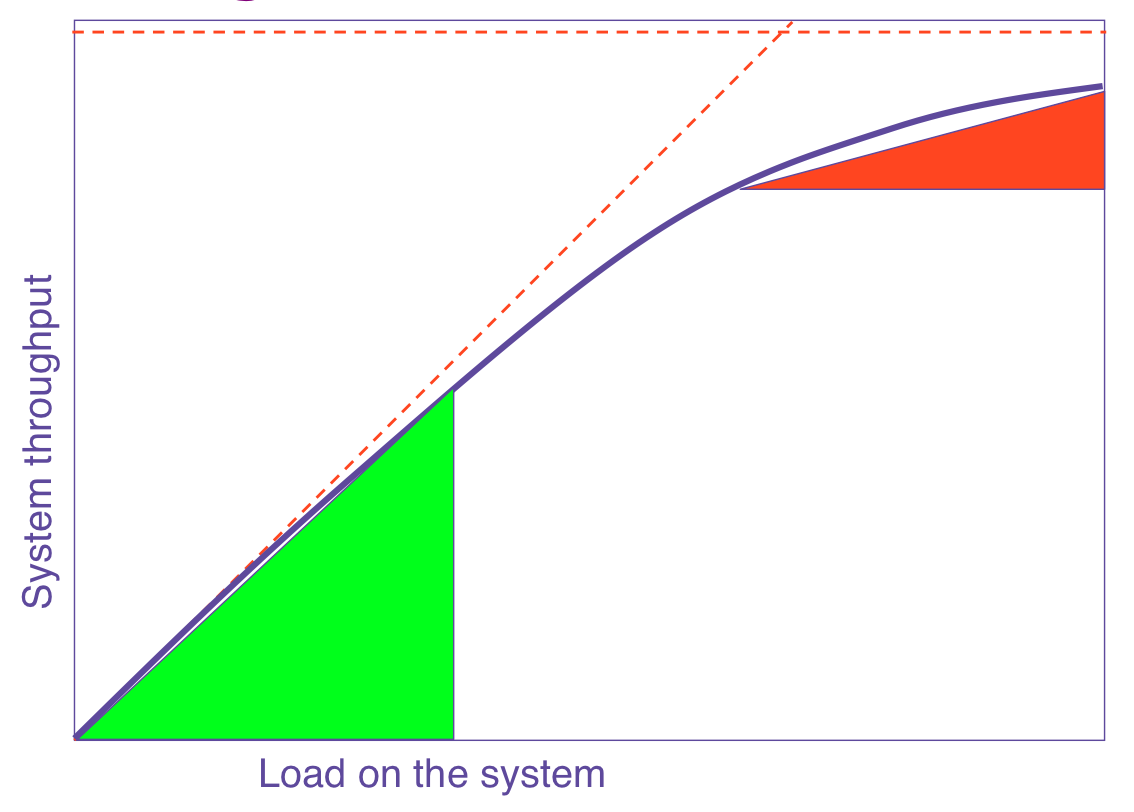
Scalability for QuantHeads: How to Do It Between Spreadsheets Why are there no 30 ft giants like the one in " Jack and the Beanstalk"? Why are there no 2,000 ft(?) beanstalks, for that matter? Engineering weight-strength models tell us their scalability reaches a critical point and they would BOTH collapse. How big can your web site scale before a performance collapse? How do you know? Can you prove it? Measurement alone is NOT sufficient. How do you know those data are correct? You need both: Data + Models == Insight. I'll show you how to prove it using simple spreadsheets. This technique leads to the concept of scalability zones. Here's what Websphere scalability looks like when it's quantified. And it's real.